新闻通告花呗可以套现吗?为什么大家都说花呗不能套现?一文读懂!
发布时间:2021-10-04来源:未知 编辑:生活头条
英特尔用ViT做密集预测效果超越卷积,性能提高28%,mIoU直达SOTA

用全卷积网络做密集预测(dense prediction),优点很多。
但现在,你可以试试Vision Transformer了——
英特尔最近用它搞了一个密集预测模型,结果是相比全卷积,该模型在单目深度估计应用任务上,性能提高了28%。

其中,它的结果更具细粒度和全局一致性。
在语义分割任务上,该模型更是在ADE20K数据集上以49.02%的mIoU创造了新的SOTA。
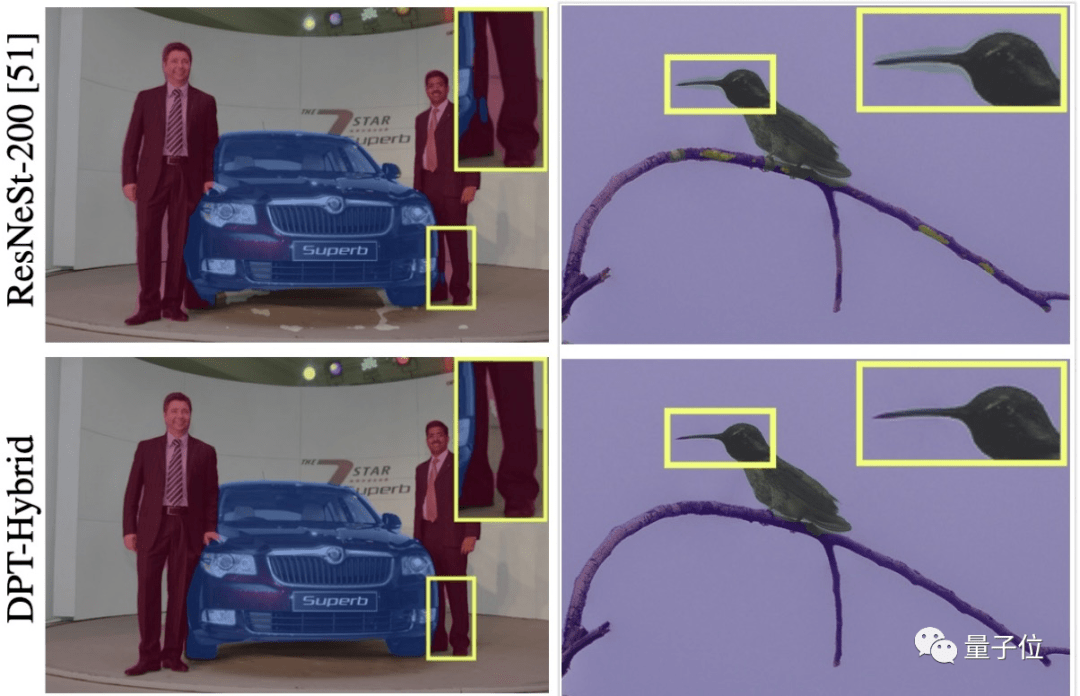
这次,Transformer又在CV界秀了一波操作。
沿用编码-解码结构
此模型名叫DPT,也就是dense prediction transformer的简称。
总的来说,DPT沿用了在卷积网络中常用的编码器-解码器结构,主要是在编码器的基础计算构建块用了transformer。
它通过利用ViT为主干,将ViT提供的词包(bag-of-words)重新组合成不同分辨率的图像特征表示,然后使用卷积解码器将该表示逐步组合到最终的密集预测结果。
模型架构图如下:
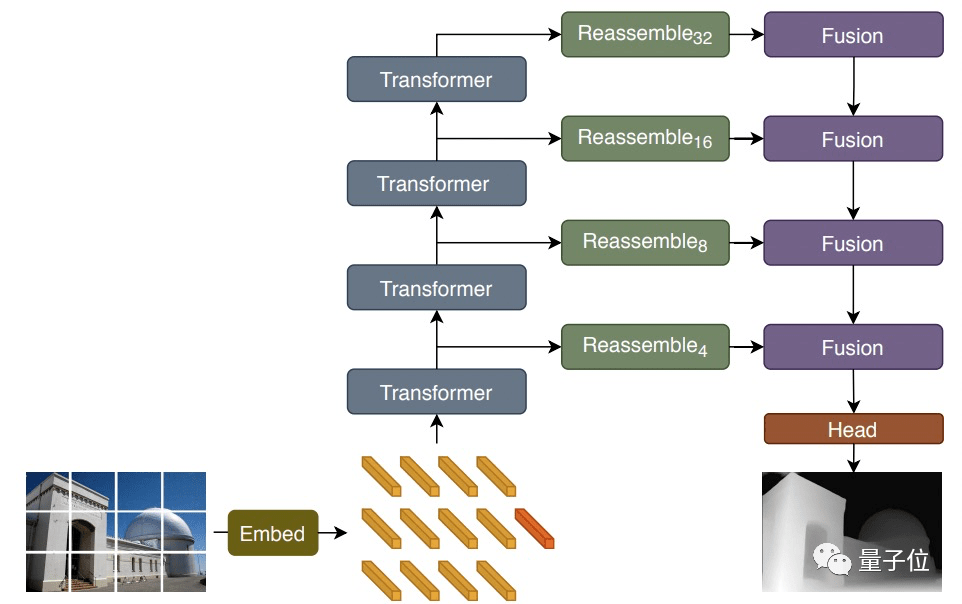
具体来说就是先将输入图片转换为tokens(上图橙色块部分),有两种方法:
(1)通过展开图像表征的线性投影提取非重叠的图像块(由此产生的模型为DPT-Base与DPT-Large);
(2)或者直接通过ResNet-50的特征提取器来搞定(由此产生的模型为DPT-Hybrid)。
然后在得到的token中添加位置embedding,以及与图像块独立的读出token(上图红色块部分)。
接着将这些token通过transformer进行处理。
再接着将每个阶段通过transformer得到的token重新组合成多种分辨率的图像表示(绿色部分)。注意,此时还只是类图像(image-like)。
下图为重组过程,token被组装成具有输入图像空间分辨率1/s的特征图。

最后,通过融合模块(紫色)将这些图像表示逐步“拼接”并经过上采样,生成我们最终想要的密集预测结果。
ps.该模块使用残差卷积单元组合特征,对特征图进行上采样。